PPO(Proximal Policy Optimization)をTensorflow2.3.0で実装しました。
損失関数内の方策エントロピー項の有無で訓練成果がどう変わるか、比較しています。
本モデルは、行動が連続値を取る環境を対象としています。
本稿では、OpenAI GymのBipedalWalkerを使用しています。
※PPOでは普通に行われる並列化Agentによる経験データ(Trajectory)収集は行っていません。Agentは単体です。
※理論の説明は基本的にしていません。他のリソースを参考にしてください。
ネットや書籍でなかなか明示されておらず、私自身が実装に際し情報収集や理解に不便を感じたものを中心に記載しています。
損失関数内の方策エントロピー項の有無で訓練成果がどう変わるか、比較しています。
本稿の実験においては、以下の環境を使用しています。
| 環境名 | 外観 | 状態の次元 | 行動の次元 | 1エピソードでの上限ステップ数 | 目的 |
|---|---|---|---|---|---|
| BipedalWalker |  |
24 | 4 | 2000 | 2足歩行して遠くまで行く |
| 未訓練モデルでPlay すぐ転倒し前に進めない |
PPO訓練済モデルでPlay 2足歩行してゴールに到達 |
|
|---|---|---|
 |
 |
 |
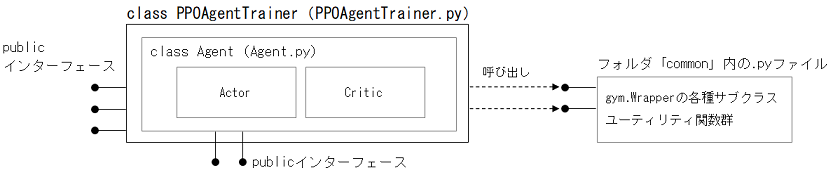
Trainerは、AgentをPPOメソッドに従い訓練します。
Agentの中身は、Actor-Criticです(両者独立したNN)。
PPOでは普通に行われる並列化Agentによる経験データ収集は行っていません。Agentは単体です。
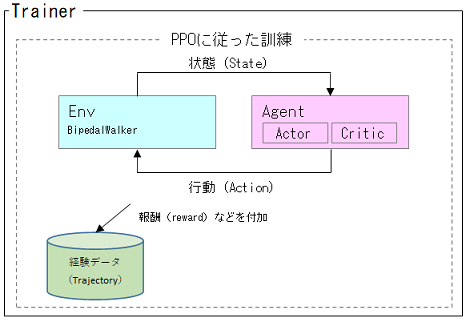
Actor-Criticで、ActorとCriticは別々のNNにしています。
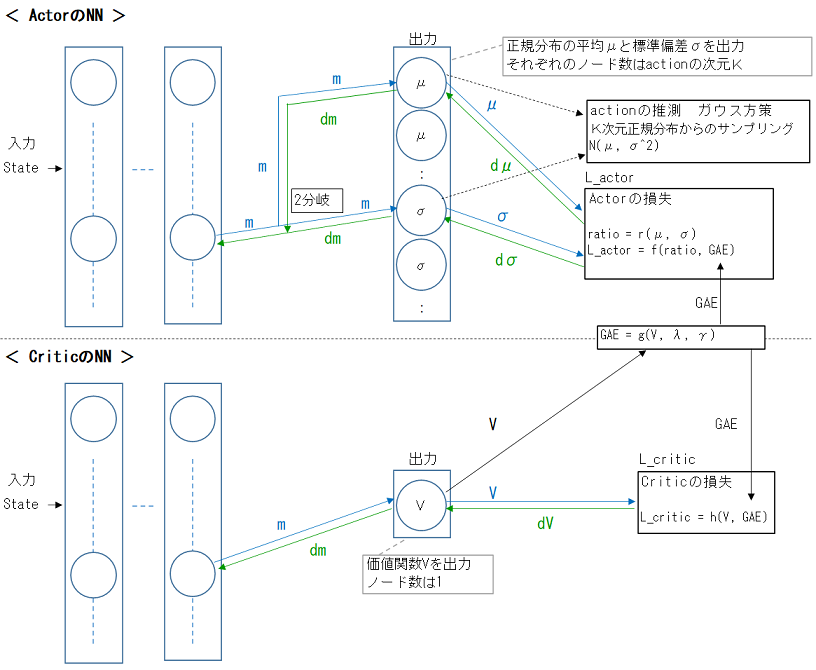
Actor側では、行動はガウス方策に従います。
よって、Actorの出力は、正規分布の平均μと標準偏差σとなります。
行動の次元数をK(=4)とすると、平均μと標準偏差σの1セットがK(=4)個ある、ということになります。
Critic側は、単純に状態価値関数値を出力するだけです。
Actor側、Critic側双方で、GAE(Generalized Advantage Estimation)を使用しています。
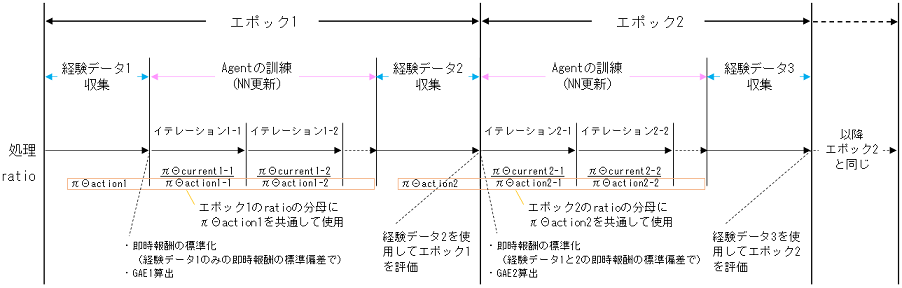
1エポック内で、以下のことを上から順に行います。
- (初回エポックのみ)経験データ(Trajectory)収集
- Agentの訓練
- 経験データ(Trajectory)収集
このエポックの評価と、次のエポックでのAgentの訓練のため
これを複数エポック繰り返します。
BipedalWalkerは、失敗時(転倒時)、-100というとても大きな絶対値の即時報酬を返してエピソードを終了します。
このように一連の経験データ中に数値規模が著しく大きい即時報酬がポツンポツンとある場合、それは実質”外れ値”となります。
後述する「即時報酬の標準化」を通すと、他の標準化報酬の数値規模が著しく小さくなってしまいます。
よって、gym.Wrapperのサブクラスを作成し、以下のような即時報酬を返すようにしました。
| 事象 | 即時報酬 |
|---|---|
| エピソード途中のステップ | オリジナルのgym.Wrapperのrewardと同じ |
| エピソード終端 成功時 (ゴールに到達した) |
+1 |
| エピソード終端 失敗時 (ゴールに到達しなかった) |
-1 |
※gym.Wrapperの自作サブクラスは、common/env_wrappers.pyにて定義されています。
ActorのLossをclipするのに使用されるratioは、以下のように算出しています。

稼得した即時報酬の標準化を行っています。
この標準化された即時報酬を使用して、GAE(Generalized Advantage Estimation)の算出をします。
ただし、この標準化において、平均を引き算しません。
平均を引くと、実際の即時報酬とはプラスマイナスの符号が逆になってしまう標準化報酬が出てきてしまうからです。
まずは、方策エントロピー項無しで、訓練してみました。
| 項目 | 値など |
|---|---|
| エポック数 | 500 |
| 経験データサイズ | 20480 |
| バッチサイズ | 2048 |
| イテレーション回数/エポック | 10 |
| Clip Rangeのε | 0.2 |
| GAE算出でのλ | 0.95 |
| GAE算出での報酬の割引率γ | 0.99 |
| GAEの標準化 | 無し |
| 方策エントロピー項の係数c | 0 |
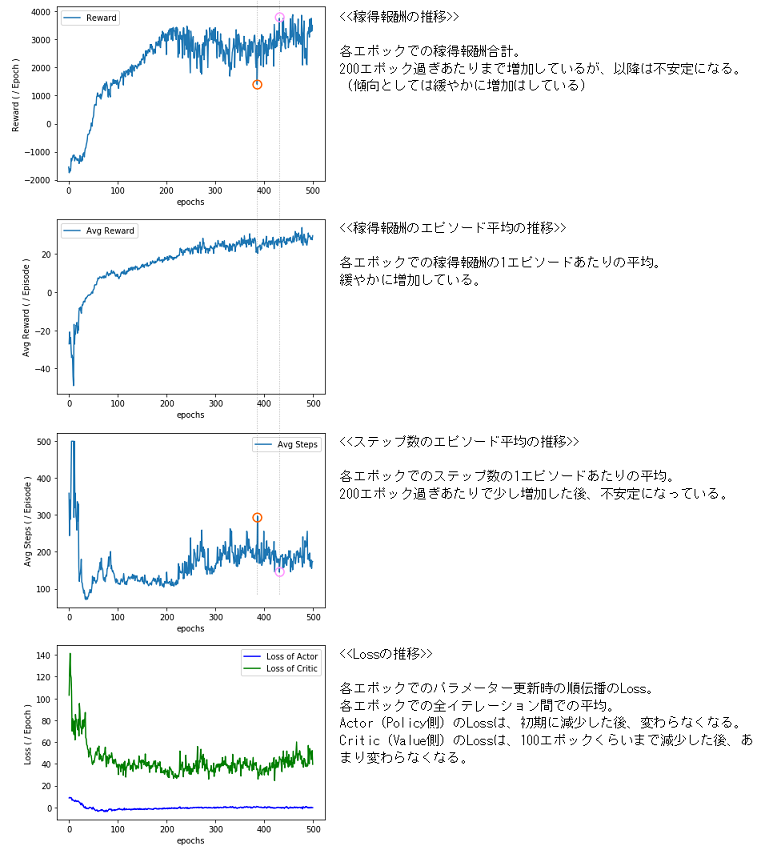
以下のような結果になりました。
- 1エポックあたりの稼得報酬は、途中まで増加した後、不安定になっている
- 稼得報酬の1エピソード平均は、ゆるやかに増加している
- ステップ数の1エピソード平均は、あるタイミングで少し増加した後、不安定になっている
また、グラフからは分かりにくいですが、ある程度訓練が進むと、「ステップ数エピソード平均が大きいと、そのエポックの稼得報酬合計が少な目」という傾向になっています(グラフを跨いだ縦の点線を参考に)。
これらのことから、1ステップあたりの報酬はマイナスになることが多く、「傷口が広がる前に早めにコケて稼得報酬合計の高さを維持する」ことを学んでしまったのか、と推測しました。
この状況を打破するには、「1つの方策に凝り固まることなく、いろんな手を打たせる」のが有効か、と推測しました。
こうして、下記の方策エントロピー項を追加することにしました。
次に、方策エントロピー項有りで、訓練してみました。
Actor(Policy側)のLossにおいて、以下のように、現在の方策のエントロピーをマイナスします。
マイナスするのは、方策が確定的でない場合に比べて、方策が確定的である場合のLossが大きくなるようにするためです。

方策エントロピー項の係数c以外、全て同じです。
| 項目 | 値など |
|---|---|
| エポック数 | 500 |
| 経験データサイズ | 20480 |
| バッチサイズ | 2048 |
| イテレーション回数/エポック | 10 |
| Clip Rangeのε | 0.2 |
| GAE算出でのλ | 0.95 |
| GAE算出での報酬の割引率γ | 0.99 |
| GAEの標準化 | 無し |
| 方策エントロピー項の係数c | 0.1 |
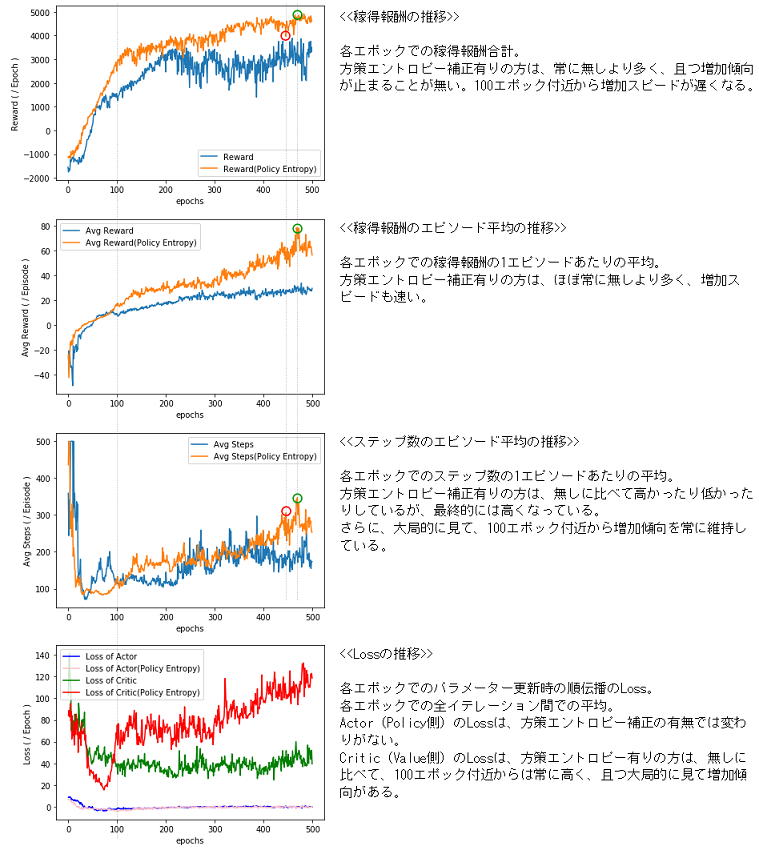
以下のような結果になりました。
- 1エポックあたりの稼得報酬
方策エントロピー項有りの方は、常に無しより多く、且つ増加傾向が止まることが無い。100エポック付近から増加スピードが遅くなる。 - 稼得報酬の1エピソード平均
方策エントロピー項有りの方は、ほぼ常に無しより多く、増加スピードも速い。 - ステップ数の1エピソード平均
方策エントロピー項有りの方は、無しに比べて高かったり低かったりしているが、最終的には高くなっている。
さらに、大局的に見て、100エポック付近から増加傾向を常に維持している。 - Actor(Policy側)のLoss
方策エントロピー項の有無では変わりがない。 - Critic(Value側)のLoss
方策エントロピー項有りの方は、無しに比べて、100エポック付近からは常に高く、且つ大局的に見て増加傾向がある。
「1エポックあたりの稼得報酬」「稼得報酬の1エピソード平均」「ステップ数の1エピソード平均」の3つすべてがほぼ最高値という3冠王的エポック(グラフの緑の〇)まで出てきています。
「報酬とステップ数をともに大きく」というBipedalWalkerのタスクの目的に訓練の方向が正しく向いており、このまま訓練を継続していたならば、さらに報酬とステップ数を伸ばすことができたと思います。
「ステップ数エピソード平均が大きいと、そのエポックの稼得報酬合計が少な目」という傾向は、概ね解消されているように見えます(ただそのようになっているエポックもまだ残っています(グラフの赤の〇))。
Critic(Value側)のLossがむしろ増加傾向になった、というのは、稼得報酬が増えたからでは、と思います。
Criticでは、Trajectory収集時のCritic出力値 + それをもとに算出したGAE が教師信号です。
よって、Criticのパラメーター更新時のCriticのLossはGAEの2乗に近い値になっているだろう、と推測できます。つまり、GAEが大きくなるほどCriticのLossも大きくなる傾向になるはずです。
訓練試行回数が少なく(方策エントロピー項有りと無しとでそれぞれ2回)、断定はできませんが、「方策エントロピー項の効果が見受けられる」とは言えそうです。
ちなみに、その各々の2回は、いずれも方策エントロピー項有りが無しよりも結果は良かったです。
本リポジトリは、他者に提供するためまたは実行してもらうために作ったものではないため、記載しません。
(tensorflow-probabilityと、それに適合するバージョンのTensorFlow2.xが最低限必要です。)
training.ipynb ・・・実際にモデルの訓練をしているノートブック
PPOAgentTrainer.py ・・・Trainer
Agent.py ・・・Agent
common/
└funcs.py ・・・ユーティリティ関数など
└env_wrappers.py ・・・gym.Wrapperの各種自作サブクラス(報酬設計の変更時に使用)
※本リポジトリに公開しているプログラムやデータ、リンク先の情報の利用によって生じたいかなる損害の責任も負いません。これらの利用は、利用者の責任において行ってください。