集用SpringAI搭建系统,依靠线程池\负载均衡等技术进行请求优化,用于解决科研&开发过程中对大语言模型接口进行批量化接口请求中出现的问题。
SpringAI官方文档:https://spring.io/projects/spring-ai
大语言模型接口以OpenAI为例,JDK版本为17,其他依赖版本可见pom.xml
在处理大量提示文本时,存在以下挑战:
- API密钥请求限制: 大部分AI服务提供商对API密钥的请求次数有限制,单个密钥每分钟只能发送有限数量的请求。
- 处理速度慢: 大量的提示文本需要逐条发送请求,处理速度较慢,影响效率。
- 结果保存和分析困难: 处理完成的结果需要保存到本地数据库中,并通过日志进行调用记录,进行后续的数据分析。
为了解决上述问题,本文提出了一种基于Spring框架的批量化提示访问方案,如下图所示:
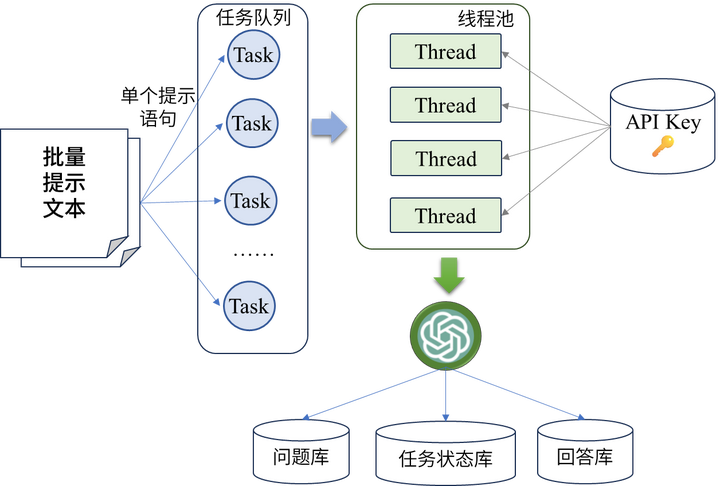
- 多线程处理提示文本: 将每个提示文本看作一个独立的任务,采用线程池的方式进行多线程处理,提高处理效率。
- 动态分配API密钥: 在线程池初始化时,通过读取本地数据库中存储的API密钥信息,动态分配每个线程单元所携带的密钥,实现负载均衡。
- 结果保存和管理: 在请求完成后,将每个请求的问题和回答保存到本地数据库中,以便后续的数据分析和管理。
- 状态实时更新: 将整个批量请求任务区分为进行中、失败和完成状态,并通过数据库保存状态码实时更新任务状态,方便监控和管理。
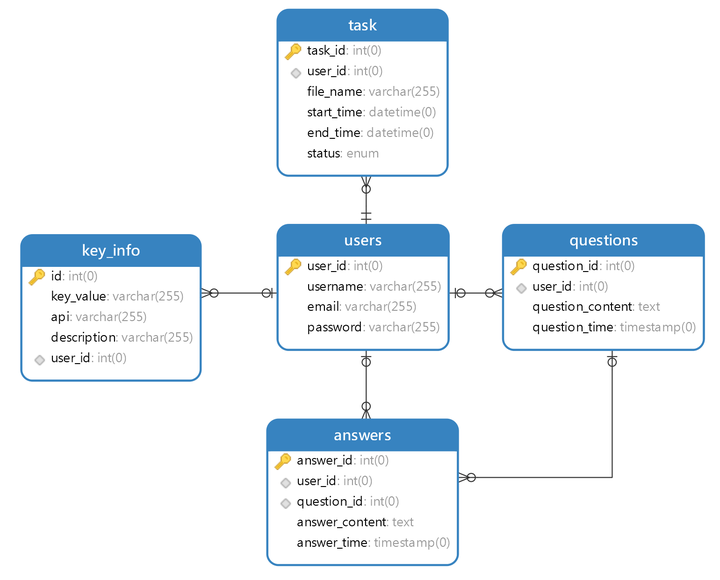
所有信息都与用户ID强绑定,便于管理和查询,ER图如下所示:
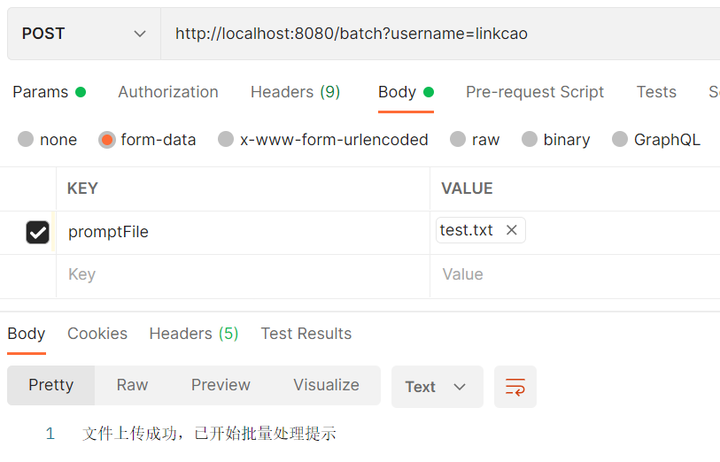
- 项目运行后,通过Postman携带
批量请求文件和username信息进行Post请求访问localhost:8080/batch接口
- 在实际应用中,可以根据具体需求对提示文本进行定制和扩展,以满足不同场景下的需求,演示所携带的请求文件内容如下:
请回答1+2=?
请回答8*12=?
请回答12*9=?
请回答321-12=?
请回答12/4=?
请回答32%2=?
- 最终返回的数据库结果,左为问题库,右为答案库.
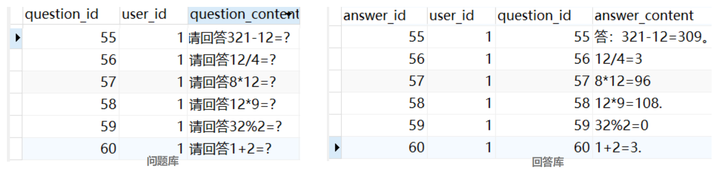
- 问题库和答案库通过
question_id和user_id进行绑定,由于一个问题可以让GPT回答多次,因此两者的关系为多对一,将问题和答案分在两个独立的表中也便于后续的垂域定制和扩展。