基于 FastAPI + Gradio + Qwen3-VL 的多平台视频解析、下载与AI内容提取系统
在线体验: 点击体验
- 多平台支持:抖音、哔哩哔哩、小红书、快手、好看视频等
- 无水印下载:智能解析视频直链,绕过水印限制
- 在线播放:支持浏览器内直接播放视频
- AI内容提取:基于 Qwen3-VL 模型智能分析视频内容
- Web 界面:基于 Gradio 的友好操作界面
- RESTful API:标准化接口,支持二次开发
- 自动文档:FastAPI 自动生成 Swagger/ReDoc 文档
| 平台 | 状态 | 平台 | 状态 |
|---|---|---|---|
| 抖音 | ✅ | 小红书 | ✅ |
| 哔哩哔哩 | ✅ | 快手 | ✅ |
| 好看视频 | ✅ |
- Docker 20.10+
- Docker Compose 2.0+(可选)
# 克隆项目
git clone https://github.com/wwwzhouhui/video-parser.git
cd video-parser
# 配置环境变量
cp .env.example .env
# 编辑 .env 文件,填入 QWEN_API_KEY
# 构建并启动服务
docker-compose up -d
# 查看日志
docker-compose logs -f# 配置环境变量
cp .env.example .env
# 编辑 .env 文件,填入 QWEN_API_KEY
# 打包镜像
docker build -t video-parser:latest .
# 运行容器(使用 --env-file 加载环境变量)
docker run -d \
--name video-parser \
-p 5001:5001 \
-p 7860:7860 \
--env-file .env \
-v $(pwd)/static/videos:/app/static/videos \
-v $(pwd)/downloads:/app/downloads \
-v $(pwd)/cache:/app/cache \
-v $(pwd)/logs:/app/logs \
--restart unless-stopped \
video-parser:latest
# 查看日志
docker logs -f video-parser在运行 Docker 前,需要创建 .env 文件:
cp .env.example .env
vim .env # 编辑配置必填配置:
| 变量名 | 说明 | 示例 |
|---|---|---|
QWEN_API_KEY |
ModelScope API 密钥 | ms-xxxxxxxx |
可选配置:
| 变量名 | 说明 | 默认值 |
|---|---|---|
QWEN_API_BASE_URL |
API 基础地址 | https://api-inference.modelscope.cn/v1 |
QWEN_MODEL_ID |
模型 ID | Qwen/Qwen3-VL-8B-Instruct |
MAX_FRAMES |
视频分析提取帧数 | 6 |
API 密钥获取地址:https://modelscope.cn/my/myaccesstoken
- Web 界面:http://localhost:7860
- API 文档:http://localhost:5001/docs
# ===== Docker Compose 命令 =====
# 停止服务
docker-compose down
# 重新构建并启动
docker-compose up -d --build
# 查看服务状态
docker-compose ps
# 查看实时日志
docker-compose logs -f
# ===== Docker 命令 =====
# 停止容器
docker stop video-parser
# 启动容器
docker start video-parser
# 重启容器
docker restart video-parser
# 删除容器
docker rm -f video-parser
# 进入容器
docker exec -it video-parser bash
# 查看容器状态
docker ps -a | grep video-parser
# 查看镜像
docker images | grep video-parser
# 删除镜像
docker rmi video-parser:latest- Python 3.10+
- ffmpeg(B站视频合并需要)
git clone https://github.com/wwwzhouhui/video-parser.git
cd video-parser
pip install -r requirements.txt# 复制环境变量示例文件
cp .env.example .env
# 编辑 .env 文件,配置 API 密钥
vim .env.env 配置项说明:
| 变量名 | 说明 | 默认值 |
|---|---|---|
QWEN_API_BASE_URL |
Qwen API 基础地址 | https://api-inference.modelscope.cn/v1 |
QWEN_API_KEY |
ModelScope API 密钥 | 无(必填) |
QWEN_MODEL_ID |
模型 ID | Qwen/Qwen3-VL-8B-Instruct |
MAX_FRAMES |
视频分析提取帧数 | 6 |
启动后端 API 服务(端口 5001):
python api.py启动 Gradio 前端(端口 7860):
python app.py- Web 界面:http://localhost:7860
- API 文档:http://localhost:5001/docs
- ReDoc 文档:http://localhost:5001/redoc
POST /api/parse
请求体:
{
"text": "https://v.douyin.com/xxx"
}请求头:
X-Timestamp: 毫秒时间戳
X-GCLT-Text: 随机明文
X-EGCT-Text: 加密后的文本
响应:
{
"retcode": 200,
"retdesc": "成功",
"data": {
"video_id": "xxx",
"platform": "抖音",
"title": "视频标题",
"video_url": "https://...",
"cover_url": "https://...",
"audio_url": "https://..."
},
"succ": true
}POST /api/download
请求体:
{
"video_url": "https://...",
"video_id": "xxx"
}响应:
{
"retcode": 200,
"retdesc": "成功",
"data": {
"download_url": "https://..."
},
"succ": true
}video-parser/
├── api.py # FastAPI 后端服务入口
├── app.py # Gradio 前端界面(含AI内容提取)
├── qwen3vl.py # AI视频内容分析工具(命令行版)
├── requirements.txt # Python 依赖
├── Dockerfile # Docker 镜像配置
├── docker-compose.yml # Docker Compose 配置
├── docker-entrypoint.sh # Docker 启动脚本
├── configs/ # 配置文件
│ ├── general_constants.py
│ ├── logging_config.py
│ └── business_config.json
├── src/
│ ├── api/ # API 路由
│ ├── downloaders/ # 各平台下载器实现
│ │ ├── base_downloader.py
│ │ ├── douyin_downloader.py
│ │ ├── bilibili_downloader.py
│ │ ├── xiaohongshu_downloader.py
│ │ ├── kuaishou_downloader.py
│ │ └── haokan_downloader.py
│ └── downloader_factory.py
├── utils/ # 工具函数
│ ├── web_fetcher.py
│ ├── vigenere_cipher.py
│ └── common_utils.py
├── static/ # 静态资源
│ └── videos/ # 下载的视频
├── downloads/ # Gradio 下载目录
└── cache/ # 播放缓存目录
| 平台 | 示例地址 |
|---|---|
| 抖音 | https://www.douyin.com/note/7580598241298069157 |
| 哔哩哔哩 | https://www.bilibili.com/video/BV1TaqYBcEJc |
| 小红书 | https://www.xiaohongshu.com/explore/68ab2dd1000000001c0045d0 |
| 快手 | https://www.kuaishou.com/short-video/3x8zha3ipq6bg8q |
| 好看视频 | https://haokan.baidu.com/v?vid=13766973483433940333 |
- 在
src/downloaders/下创建新的下载器类 - 继承
BaseDownloader基类 - 实现
get_title_content()、get_real_video_url()、get_cover_photo_url()方法 - 在
src/downloader_factory.py中注册新平台 - 在
configs/business_config.json中添加域名映射
# 测试后端 API
curl -X POST http://localhost:5001/api/parse \
-H "Content-Type: application/json" \
-H "X-Timestamp: $(date +%s)000" \
-H "X-GCLT-Text: test" \
-H "X-EGCT-Text: test" \
-d '{"text": "https://www.bilibili.com/video/BV1TaqYBcEJc"}'本项目集成了 Qwen3-VL 视觉语言模型,可智能分析视频内容并生成文字描述。
-
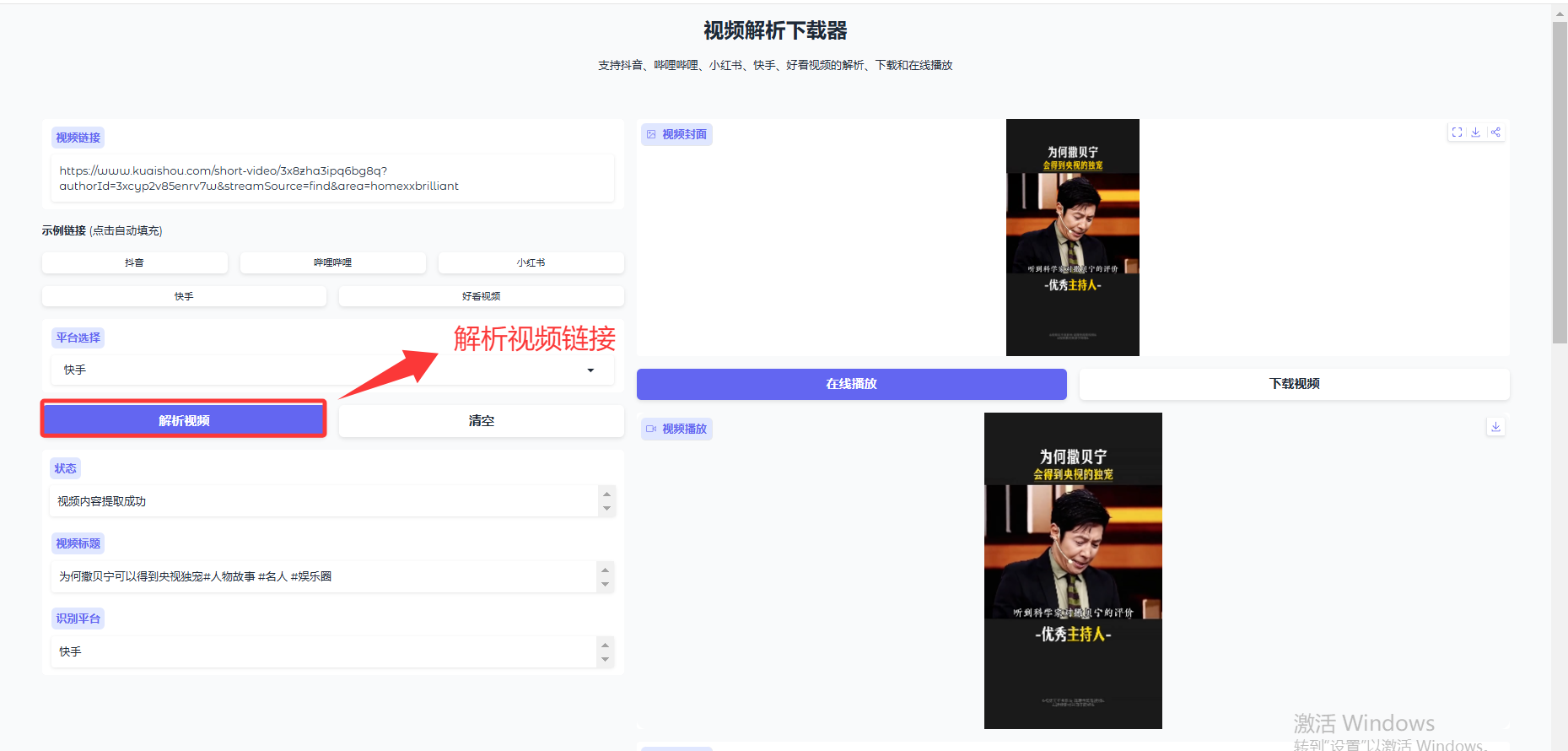
解析视频链接
-
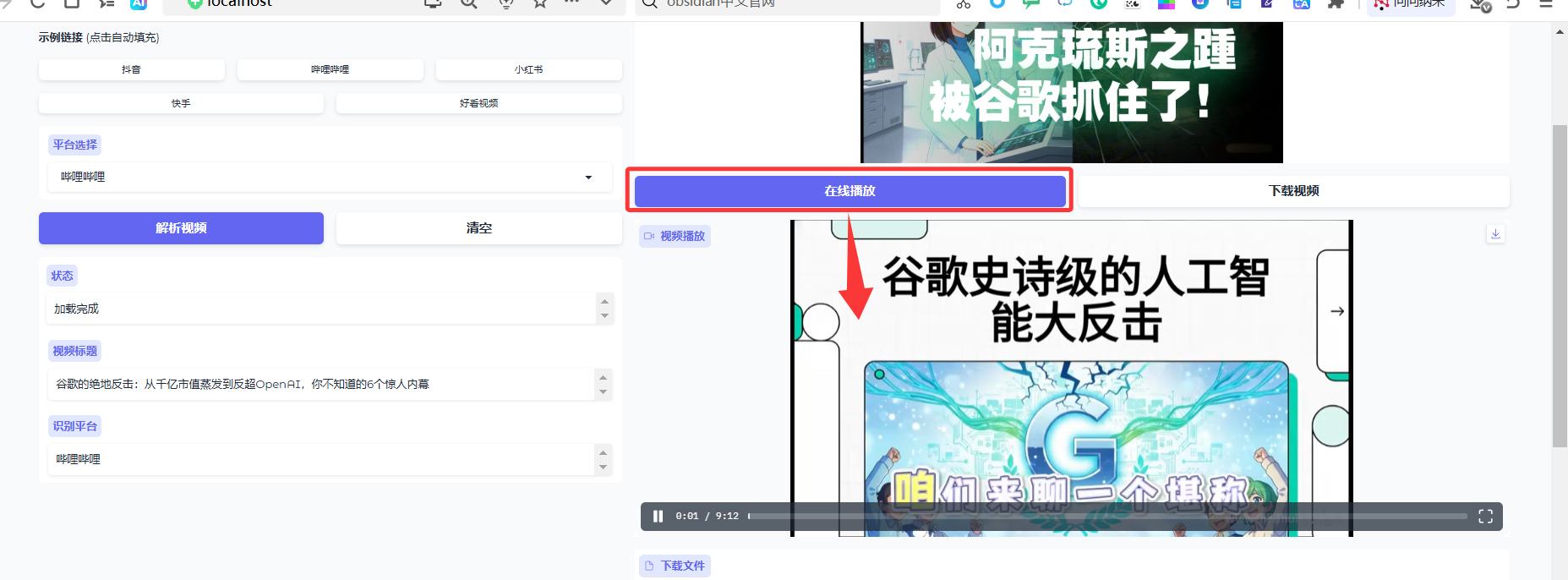
点击「在线播放」加载视频
-
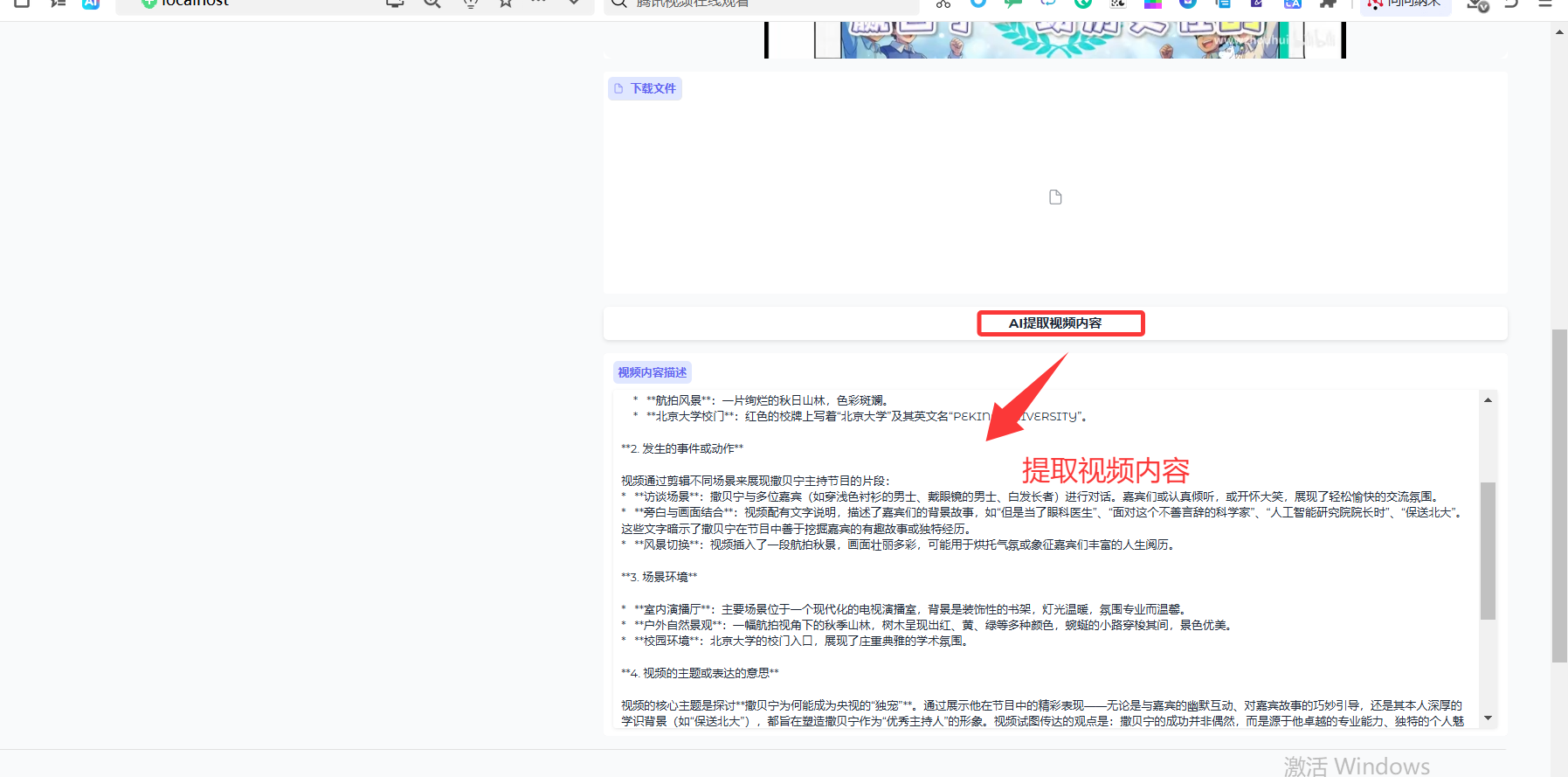
点击「AI提取视频内容」按钮
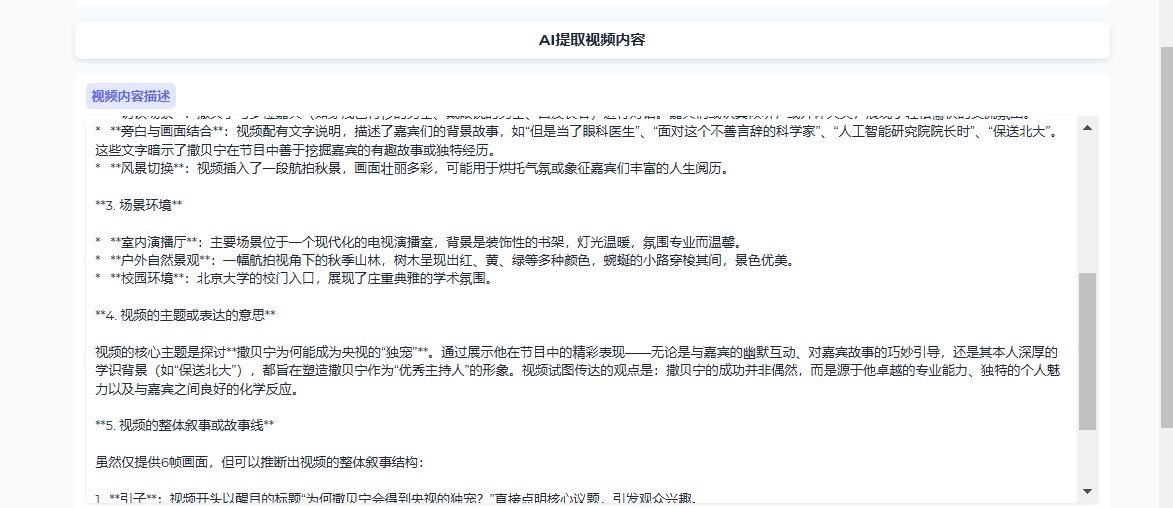
-
等待 AI 分析完成,查看内容描述
# 列出所有视频文件
python qwen3vl.py --list
# 分析指定视频
python qwen3vl.py --video downloads/video.mp4
# 使用自定义提示词
python qwen3vl.py --video video.mp4 --prompt "这个视频讲的是什么故事?"
# 指定提取帧数(默认6帧)
python qwen3vl.py --video video.mp4 --frames 8
# 交互式模式
python qwen3vl.py --interactive- 使用 ffmpeg 从视频中均匀提取关键帧
- 将帧图片转换为 base64 编码
- 调用 Qwen3-VL API 分析图片内容
- 生成视频内容的详细描述
- B 站视频为音视频分离,需要安装 ffmpeg 进行合并
- 部分平台可能需要特殊的请求头(Referer)才能下载
- 视频链接有时效性,解析后请尽快下载
- AI内容提取需要先播放视频(加载到本地缓存)
- AI内容提取依赖 ffmpeg 提取视频帧
本项目基于 MIT License 开源。
免责声明:本项目仅供学习交流使用,请勿用于非法用途。因使用本项目造成的任何后果,由使用者自行承担。