
A collaborative work is done by Vivian Chuhan Yu (chuhany2) and Chenyu Zhao (chenyu5). Being a Psych major, Vivian applied her expertise in designing the connection between human emotions and movie genres. She is also responsible for designing the graphical user interface using tkinter, and presenting the information in Treeview. Chenyu is responsible for building the web scraper, designing the logistic regression algorithm, and implement the Cosine Similarity analysis. He is also responsible for writing the documentation and narrating the presentation.
This is a Python-based movie recommendation system that implemented text-retrieval techniques and Graphical User Interface. One special thing about this system is that its recommendations were tailored around users' emotion of the moment. There are so many existing movie recommender systems available on the market, but only a small number of them were designed based on users' psychological needs. The main objective of this project is to fill this gap by making traditional recommender system more user-driven.
There are 10 categories of emotion the system presented to users to choose from. These are 5 postive emotions ("Happy", "Satisfied", "Peaceful", "Excited", "Content") and 5 negative emotions ("Sad", "Angry", "Fearful", "Depressed", "Sorrowful"). These emotions taken as inputs from the GUI interface we built through tkinter (please refer to interface.py):
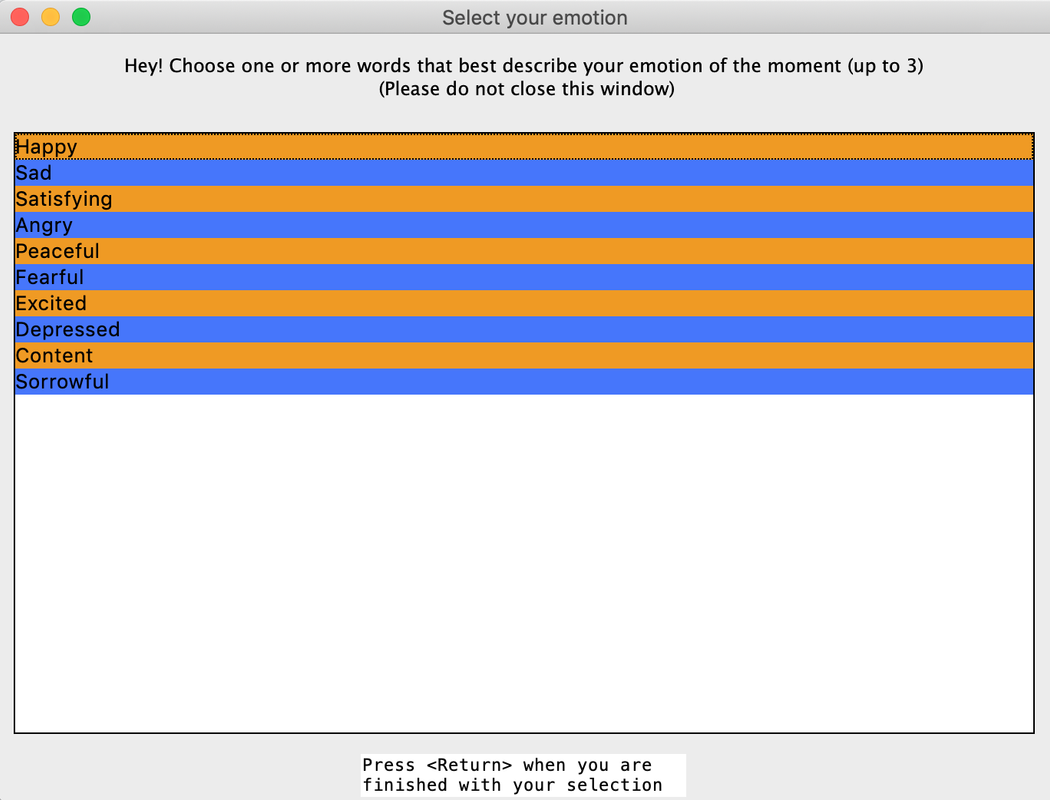
The correspondence of every emotion with genre of movies are set up as below:
- Happy - Horror
- Sad - Drama
- Satisfied - Animation
- Angry - Romance
- Peaceful - Fantasy
- Fearful - Adventure
- Excited - Crime
- Depressed - Comedy
- Content - Mystery
- Sorrowful - Action
Based on the inputted emotion, the system is going to be selected from the corresponding genre based on their ratings given by two websites: IMDB and Rotten Tomatoes. The reason why we are collecting movie information from both websites is that we believe the system is able to capture a more full-scaled opinions from movie lovers.
Because we intend to scrape two websites with different web structure, we developed one IMDB crawler and another RT crawler to extract movie information. Check out scraper.py for more details.
Here are two example movie pages of IMDB and Rotten Tomatoes:
As you can see, comparing to IMDB, Rotten Tomatoes includes the majority of movie information in each movie profile link. Our crawler had to look up each link to capture hidden information, such as movie length, maturity grading, cast, etc. Therefore, it is unavoidable that the program takes more time to scrape RT pages.
We would pull user rating scores from both IMDb and Rotten Tomatoes. Due to the different rating scales used by IMDb and Rotten Tomatoes, we would first convert both scores to a 10-point scale for the ease of comparison. We would also take the number of ratings into consideration, as larger number of ratings tends to make the overall rating more credible. Therefore, we would run logistic regression function on the number of ratings, and add it as an additional weightage to the final movie score.
After users indicate their moods, the program is going to look up the corresponding link to the movie page and present movie information as Treeview, which is a module included by the tkinter library displaying a hierarchical collection of items.
Here is an example output of the list of recommended movies:
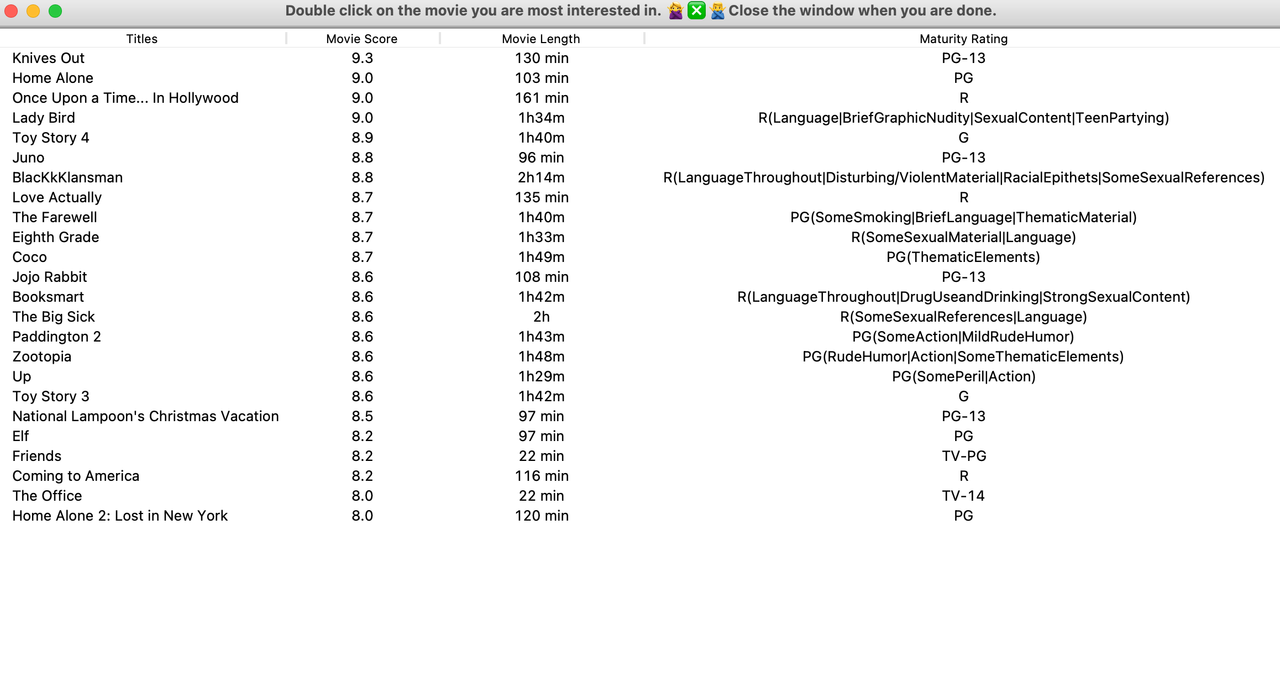
Note: Not every movie has all information listed. If the crawler cannot find relevant information, it will automatically fill the space with "Not Found".
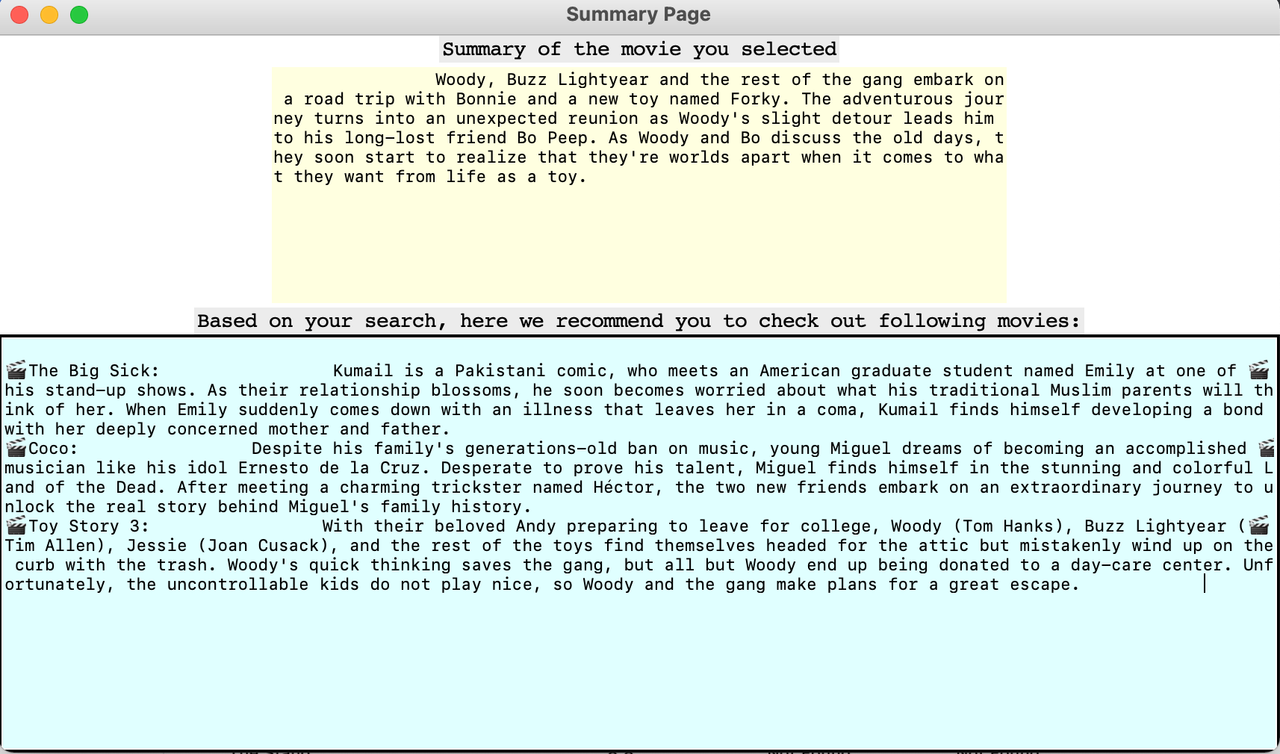
After users chose their favorite movie from the list, we would run a Cosine Similarity analysis to recommend 3 similar movies based on the summary.
Here is an example of movies similar to Toy Story 4:
The work is equally distributed between the two teammates, and we were able to complete our mood-based movie recommender system as intended. We chose not to build a seperate mobile application, but instead spend the time working on additional features like cosine similarity and logistic regression. In the end, we have obtained the expected outcome.
Please check out requirements.txt for information.
You can install all packages at once using $ pip install -r requirements.txt.
Please use Python 3. Otherwise you will need to import tkinter.ttk separately because it is not a submodule of tkinter in Python2
After making sure you have all packages installed, activate the program through main.py.
The program will start running immediately.
The scraping process may take up to 30 seconds. Please do not close the tkinter window when the program is running.