LearningRateScheduler为回调函数callbacks中对学习率进行更改的函数,其又名学习速率定时器,是可以在每一次的epoch中都可以对学习率进行更改的函数,而如何更改则取决于你定义的函数。
 由上方官方文档介绍知,LearningRateScheduler接受两个形参,一位schedule,一为verbose。verbose在这里不多讲,而schedule则是自己定义的函数,schedule接受一个形参(epoch),同时,Model也可传入schedule中,返回一个浮点数作为新一轮的学习率
使用实例如图
由上方官方文档介绍知,LearningRateScheduler接受两个形参,一位schedule,一为verbose。verbose在这里不多讲,而schedule则是自己定义的函数,schedule接受一个形参(epoch),同时,Model也可传入schedule中,返回一个浮点数作为新一轮的学习率
使用实例如图
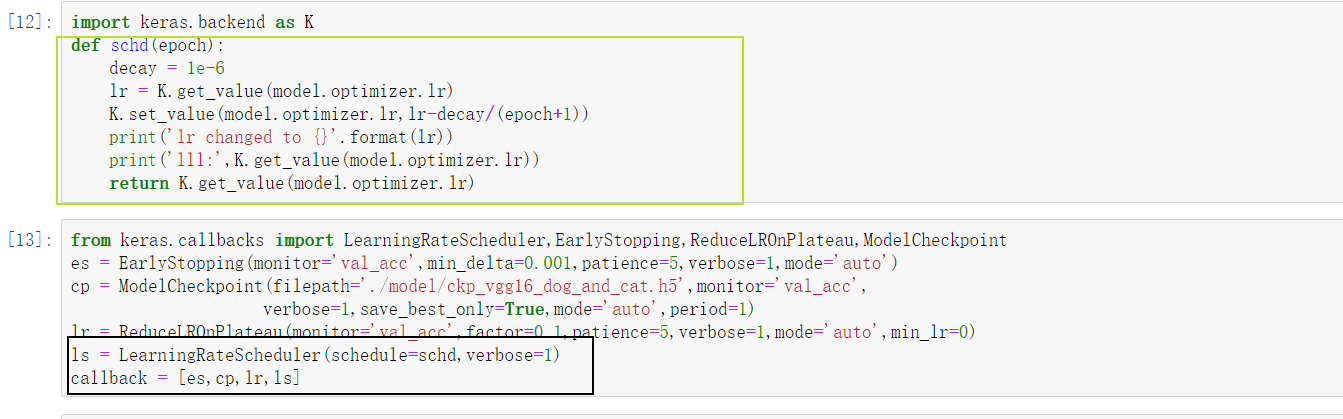
回调器中有两个函数均可对学习率进行操作更改,分别为LearningRateScheduler和ReductLROnPlateau函数,但是两者工作原理不一样。LearningRateScheduler是对每一轮的学习率都进行更改矫正。而ReductLROnPlateau如下图所示,
 其是在某几轮训练下来,准确率的提高没有达到期望值时才对学习率进行更改。
其是在某几轮训练下来,准确率的提高没有达到期望值时才对学习率进行更改。
其实难点仍是在于学习率的调整,太大了忽略掉全局最优解、太小了又可能在局部最优解震荡,因此难点仍是在学习率的调整,较为靠谱的思路是参考每一轮的loss,以loss作为权重调解下一轮的学习率。
参考Model的loss的话,就需要把每一轮的loss数值传入进去,但是,emmmm能力有限,不知道怎么传,希望知道的大神指导一下~~~~
只需要重点看此三行即可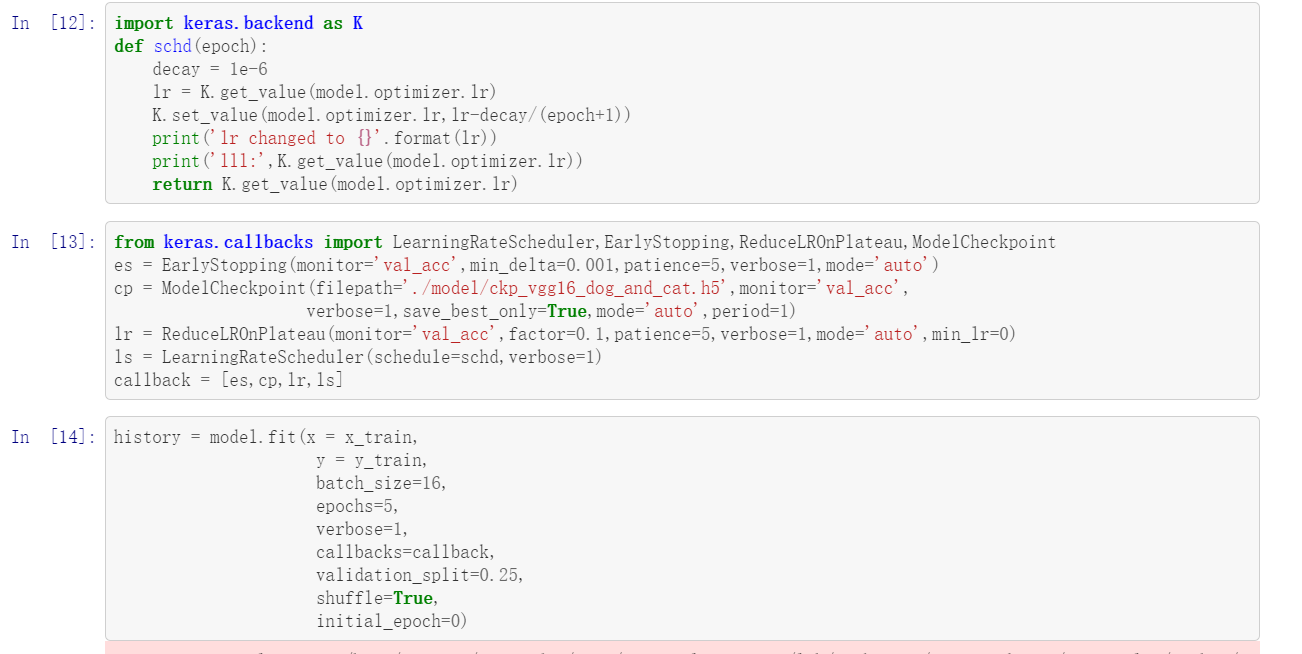
具体所有代码请见00扩展.ipynb
==========================================================
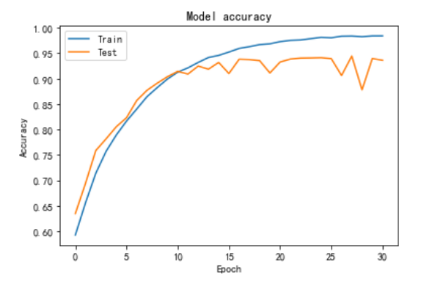
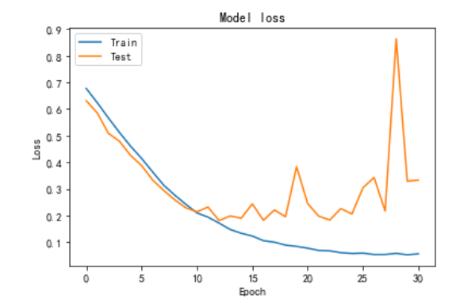
从图中可以看出,rmsprop在10轮之后,在训练集中准确率不断提高的前提下,测试集上的准确率开始稳定在90%左右,因此在10轮之后开始发生过拟合现象。
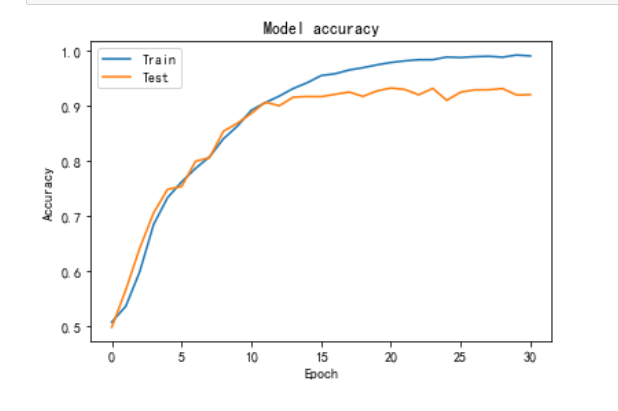
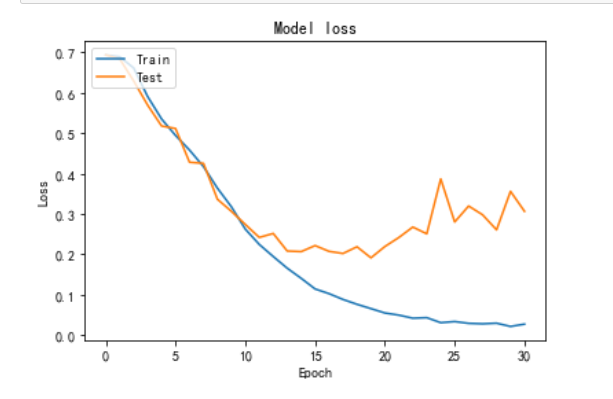
从图中可以看出,adam在10轮之后,在训练集中准确率不断提高的前提下,测试集上的准确率开始波动,但是稳定在90%左右,adam相对于rmsprop的波动更小,更加稳定一点。
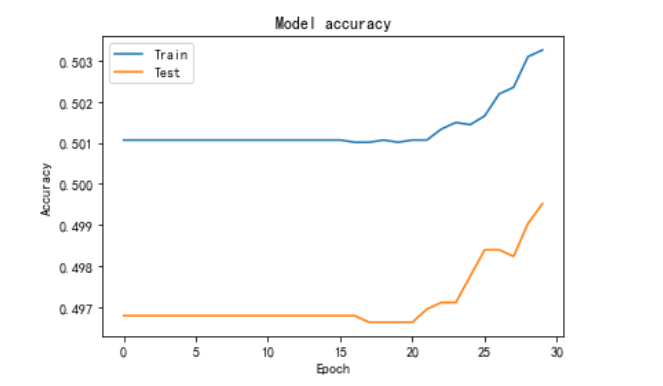
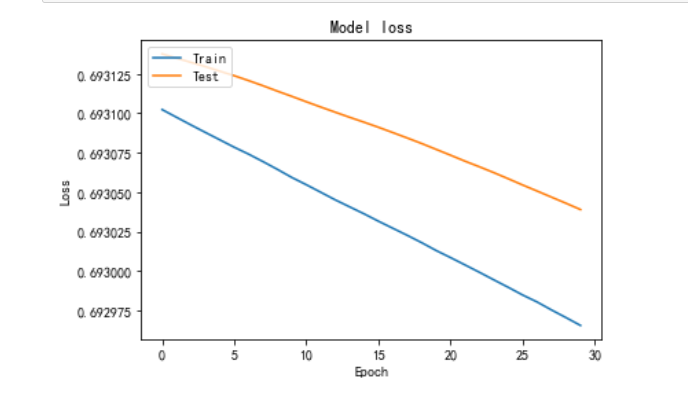
SGD在20轮时才开始模型开始上升,因此学习率应该是一开始定的太高以忽略掉最优解的情况。因此SGD优化器中学习率初值应设定为0.00008较为合适(0.0001 - 20*0.000001)
具体代码请见01扩展
三个优化器 共计93轮 大约用时4h