
unstable:

pyblade参考了王垠的在pysonar2项目中对python的语法树解析,具体来讲就是利用了他的python_dump.py文件会对python源代码文件进行解析,即便Python官方的ast模块进行了更新, 只需对dump_python.py进行少量更改即可,不影响后续的代码审计。他的项目地址:pysonar2
Python注入问题是说用户可以控制输入,导致系统执行一些危险的操作。它是Python中比较常见的安全问题,特别是把python作为web应用层的时候这个问题就更加突出,它包括代码注入,OS命令注入,sql注入,任意文件下载等。
-
os命令注入
主要是程序中通过Python的OS接口执行系统命令,常见的危险函数有
os.system, os.popen, commands.getoutput, commands.getstatusoutput, subprocess
等一些危险函数。例如:
def myserve(request, fullname): os.system('sudo rm -f %s'%fullname)
其中fullname是可控的,恶意用户只需利用shell的拼接符就可以完成一次很好的攻击。
-
代码注入
注入点可以执行一段代码,这个一般都是由Python的序列化函数eval导致的,例如:
def eval_test(request, login): login = eval(login)
如果恶意用户从外界传入import('os').system('rm /tmp -fr')就可以清空tmp目录。
-
SQL注入
在一般的Python web框架中都对sql注入做了防护,但是千万别认为就没有注入风险,使用不当也会导致sql注入,例如:
def getUsers(user_id): sql= 'select * from auth_user where id =%s'%user_id res = cur.execute(sql)
-
任意文件下载
程序员编写了一个下载报表或者任务的功能,如果没有控制好参数就会导致任意文件下载,例如:
def export_task(request, filename): return HttpRespone(fullname)
很显然在参数不断传递过程中,通过普通的正则表达式去匹配危险代码已经无能为力了。而语法树的分析可以解决参数传递的问题,是污点分析的基础。
-
语法树的表示-文件
一个文件中可以有函数,类,它是模块的组成单位。大体结构如下:{"body": [{},{}], "filename": "test.py", "type": "module"}
-
语法树的表示-函数
{"body": [...], ... ,"name": "func1","args": {"vararg": null, "args":[...], "kwarg": null}, "lineno": 10, "_field":[], "type": "FunctionDef"}
-
语法树的表示-类
{"body":[...], ... ,"decorator_list":[],name": "AstTree","bases":[...],"lineno" : 6, "name_node": {...}, "type":"ClassDef"} 在类的语法树中,包含body,decorator_list,lineno,name,base等字段type是ClassDef,表明该结构为class,body中则包含着函数的结构体,bases则是继承的父类。
-
语法树的表示-分支
下面我们将以一个if结构片段代码作为示例,来解释Python源码到其语法树的对应关系。片段代码:
if type not in ["RSAS", "BVS"]: HttpResponse("2")
它生成的代码如下所示: {"body": [...], "lineno": 5, "test": { "ops": [{ "type": "NotIn" }], "comparators": [...], "opsName": [...],}, "type": "If", "orelse": [] }
在这个语法树结构中,body里包含着if结构中的语句HttpResponse("2"),type为Compare表示该结构体为判断语句,left表示左值即源码中的type,test结构体中则是用来进行if判断, test中的ops对应着源码中的not in,表示比较判断,comparators则是被比较的元素。这样源码就和Python语法树一一对应起来,有了这些一一对应的基础,就有了判断Python注入问题的原型。
污点分析有三大元素:污点源、敏感规则、敏感宿。
污点源是指可能引起程序产生各类安全问题的数据来源(如键盘的输入,秘密数据或恶意数据),污点源主要分四大类:
- 从文件中读取数据的库函数,如文件内容读取函数,路径读取函数等等。
- 从键盘读取数据的库函数。
- 从网络读取数据的库函数,如网络数据接收函数:web.input从网络获取数据,socket.read读取socket包,requests.get读取服务器响应的内容。
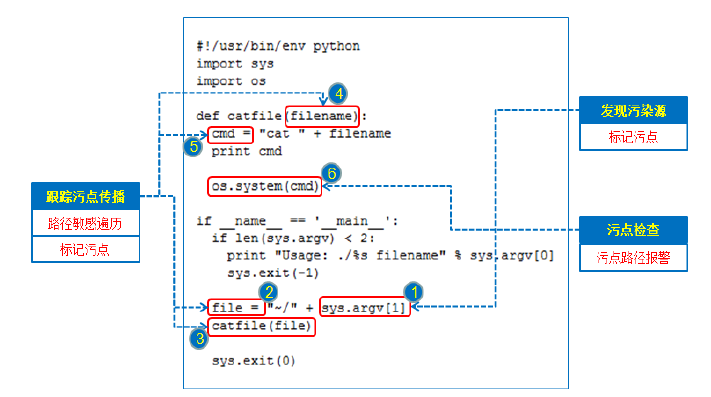
- 程序的命令行参数, Python的命令行参数sys.argv[],sys.argv[0]表示代码本身文件路径,所以可控参数的索引从1开始。
识别出污点源后,并对相应的数据进行污点标记后,由于污点数据还参与运算指令的执行,因此还需要进行污点传播规则分析。污点传播有以下几种规则:
- 简单赋值语句。对于赋值语句,如果赋值变量是污点数据,那么被赋值的变量也被标记成污点数据。
- 二元运算语句。对于二元运算语句,如果参与运算的一个变量是污点数据,那么运算结果也被标记成污点数据。比如对于加法运算语句cmd = "cat " + filename。
- 可变对象赋值。Python中的可变对象有字典、列表可以进行拷贝进行重新赋值,形成一个新污染变量。a.copy(b)。
- 函数调用传递形式参数。在函数定义出使用的形式参数,在函数调用时会以实际参数传入,例如:cat_file(file)。
- 类的实例化。Python支持面向对象编程,类对象支持两种操作:引用和实例化。引用操作是通过类对象去调用类中的属性或者方法,而实例化是产生出一个类对象的实例。因此污点变量可以通过类进行传播。
为便于表述传播规则,引入函数 T 和布尔变量 t_v。函数 T 接受一个变量值,如果该变量值被标记为污点数据,则返回 true,否则返回 false。布尔变量 t_v 表示是否应该对变量值 v 进行污点标记,如果 t_v=true,则变量 v 也被标记为污点数据,否则,不对 v 进行污点标记。
还有敏感规则就是争对安全漏洞的形成原理制定防范规则,敏感宿就是含有可控参数的执行危险函数。
污点分析核心在于污点标记,传播路径跟踪,敏感函数三大内容。
先利用dump_python文件对Python源代码进行字典化保存,然后取相应的键和值,找到sys.argv所在的位置,标记污染源,然后分析敏感路径,最后找到敏感宿,形成污染分析的最终结果。
实现函数的概要信息时,通过递归查找出所有函数定义的行号,利用行号和文件名产生一个UUID,然后找到所有的函数调用,并把其添加到'call'的字典里的键值里。
-
字符串拼接
-
处理函数调用后赋值
解压安装压缩包,进入源代码主目录,使用python setup.py install命令进行安装。在testcode.py里包含如下代码,运行testcode.py即可对test里的样本文件进行测试。 代码示例:
from pyblade import scan
FILE = 'taintanalysis.py'
dir = os.path.abspath('.')
file = os.path.join(dir, 'tests/' + FILE)
fd = open(file, 'r+')
strings = fd.read()
files = {
FILE: strings }
scan(files)strings是待检测的代码生成的字典。生成的具体方法参见tests目录下的readme

GPL v2(通用公共授权第二版, 1991年6月)
This is free software published under GPLv2. See LICENSE.
著作权所有 (C) 1989,1991 Free Software Foundation, Inc. 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA