测试脚本: test.py
需要配置大模型key,以及上传的图片ak sk (上传图片涉及到一些公共storedao,没法开源,需要按照自己使用的自行/ai实现)
原文如下:https://mp.weixin.qq.com/s/TuGaBdzJ1xHVpeUm-grawg
上周是智谱的多模态开源周,从4.6v到Autoglm...
看到官方的博客,第一眼比较吸引我的,不是模型本身,是他们给的一个使用场景 - 图文并排。
上传一份 PDF 论文,它能生成一篇图文混排的解读文章,而且效果非常好。图片位置精准,上下文衔接自然,完全不像是机械拼接的。
过去我们想做图文混排,都是预定义一些图片,让多模态大模型生成描述,再让LLM在写文章时结合图片描述,选择合适的图片url。
流程繁琐,效果一般(主要是模型看不到这些图)。
太久没用过多模态大模型了,感觉时代似乎变了~
Z.ai 已经上线了这个能力,所以我逆向了一下原理,复刻了一下,有不少收获,给家人们分享一下。
我们可以看一下下边的视频。模型会先生成一个带工具槽位的初版,后续会有图片引用。进行调用裁剪工具,捞回来图片,最后完成终稿的撰写。
其实从Z.ai 服务请求日志,也可以看到具体的工具调用信息。

相当于类似一个ReAct Agent,调用工具截图相当于获取到observation,然后进行下一步的Action。
如果想做一个自由度没这么高的话,一个架构就是:
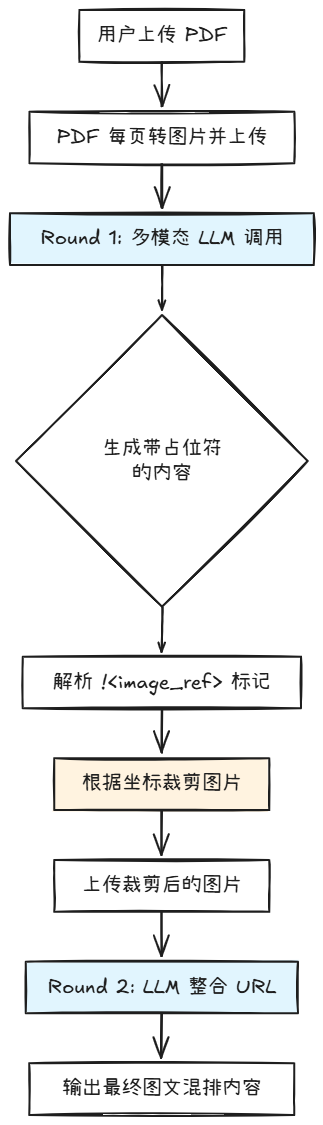
基于这个模式,我复刻了一套代码。结果跟ZAI跑出来的结果基本一致。重点是复刻过程中,我发现了几个非常有意思的点,下一章节详细介绍一下。

跑一篇20页的论文,大概消耗1毛5的样子。如果用量比较多,可以考虑智谱的 GLM Coding Plan,20 元包月起,用量是同价位 Claude Code 的三倍。而且它的视觉 MCP 不是单独的工具,是深度集成在模型能力里的。

这是Glm4.6V 最让我惊讶的能力。模型不仅能理解图片内容,还能输出图片在页面上的坐标,比如前面调用图片裁剪工具,我让模型输出的格式如下:
[页码, [[x1, y1, x2, y2]], "图片标题"]
需要注意的是:模型的输出坐标是千分位坐标(0-999 范围),需要按比例转换成像素坐标。 当然如果用官方mcp tools没这个烦恼。
def thousandth_to_pixel(coord, image_width, image_height):
"""千分位坐标转像素坐标"""
x1 = int(coord[0] / 1000 * image_width)
y1 = int(coord[1] / 1000 * image_height)
x2 = int(coord[2] / 1000 * image_width)
y2 = int(coord[3] / 1000 * image_height)
return [x1, y1, x2, y2]为什么是千分位?因为不同分辨率的图片,像素坐标会变,但千分位坐标是相对的,更具通用性。
一篇 20 页的 PDF,转成图片后全部塞进去,模型能完整理解,128k确实不是吹的。
这让我想起不久前智谱的另一个工作Glyph:把文本渲染成图片,让视觉 token 承载更多信息。
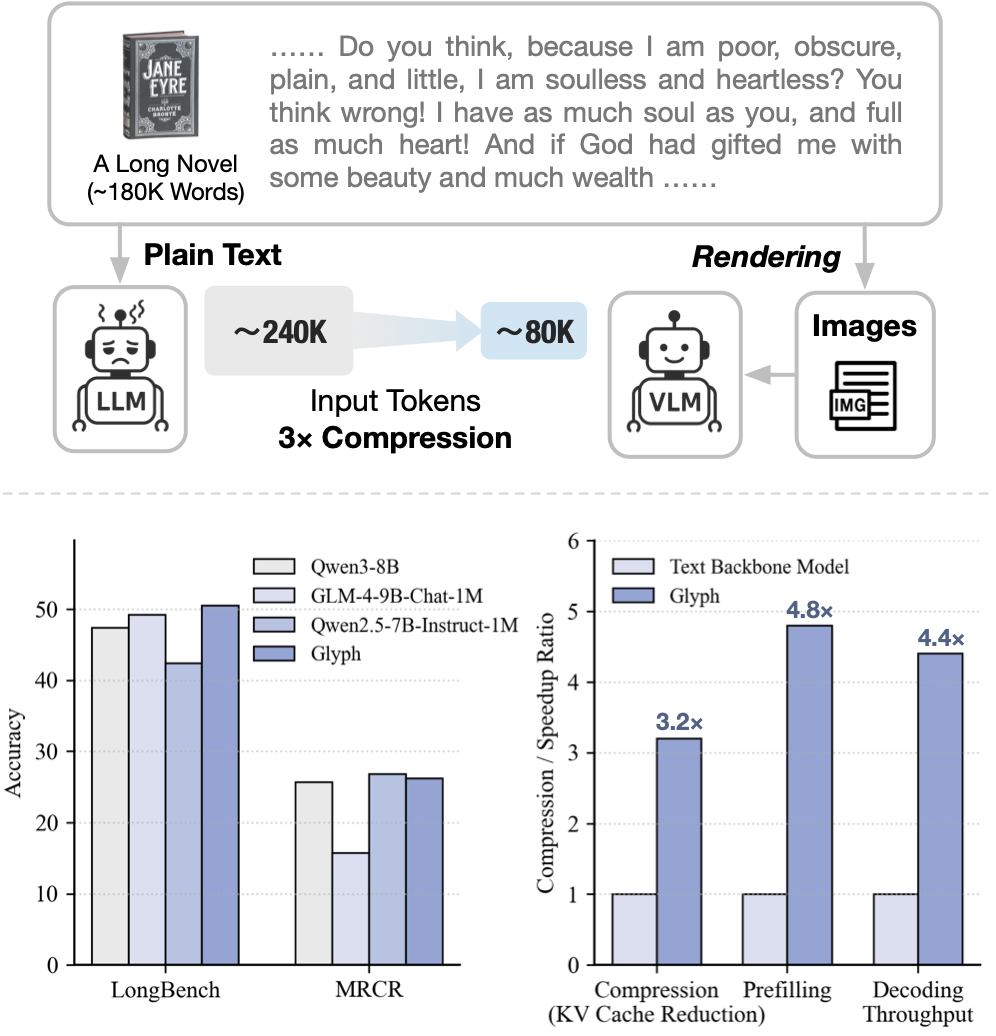
传统的 token 扩展方式已经走到算力成本的天花板。与其硬扛百万级token的计算压力,不如让 AI看文字,而不是读文字。
所以过去我们头痛的解析、分块等操作,随着多模态模型的变强,似乎迎刃而解了。
获取到裁剪后的图片之后,如果只是简单的字符串替换,直接正则就够了。
但如果用VLM,在第二轮可以验证裁剪是不是正确,可以调整图片周围的文字,可以优化图文的排版位置。
GLM-4.6V 就是一个原生的 Agent。
多模态时代的 Agent 和纯文本时代完全不一样。
模型不再只是 读 信息,而是 看 信息。它知道 Figure 2 在第 4 页的左上角,知道 Table 3 的边界在哪里,知道如何把这些视觉元素编排到文章中。
非常符合GLM4.6V的宣传语: 不止能看,更能执行。
