The Official PyTorch implementation of DIFO: Diffusion Imitation from Observations (NeurIPS'24).
Bo-Ruei Huang,
Chun-Kai Yang,
Chun-Mao Lai,
Dai-Jie Wu,
Shao-Hua Sun
Robot Learning Lab, National Taiwan University
[Paper]
[Website]
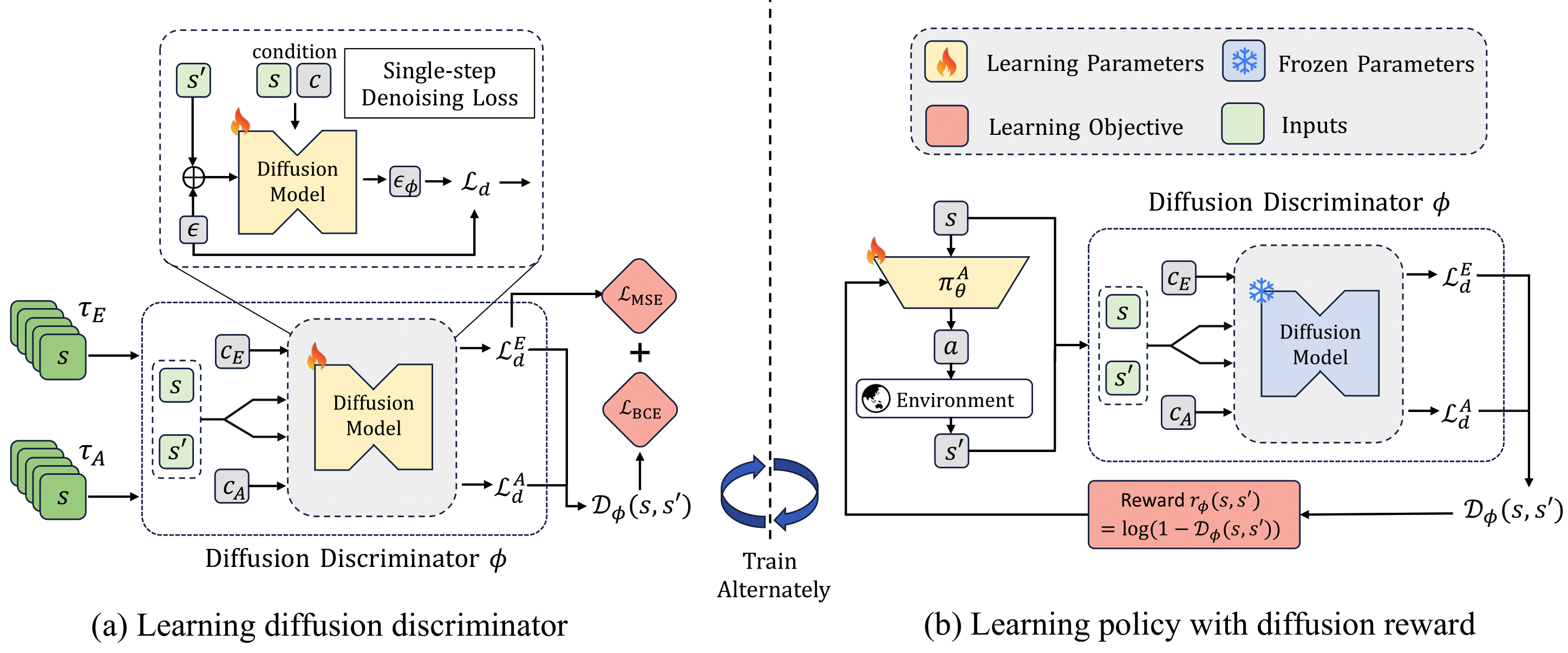
DIFO is a novel framework for imitation learning from observations that combines adversarial imitation learning with inverse dynamics regularization. It enables learning from expert observations without requiring expert actions.
@inproceeding{huang2024DIFO,
author = {Huang, Bo-Ruei and Yang, Chun-Kai and Lai, Chun-Mao and Wu, Dai-Jie and Sun, Shao-Hua},
title = {Diffusion Imitation from Observation},
booktitle = {38th Conference on Neural Information Processing Systems (NeurIPS 2024)},
year = {2024},
}- Python 3.10+
- MuJoCo 2.1+ - Physics engine
conda create -n difo python=3.10 swig
conda activate difo
pip install -r requirements.txtSetup Weights & Biases by first logging in with wandb login <YOUR_API_KEY>.
Alternatively, you can instead log to stdout by setting log_format_strs = ["stdout"] in scripts/ingredients/logging.py.
Download the datasets from the Google Drive to the datasets/ directory.
gdown --id 1Bc9pXnJZxgFUhHwJUKE98Mras1TxTC5J -O datasets --folderWe provide the configuration YAML files for training DIFO and other baselines in the exp_configs/ directory.
Including 7 tasks:
point_maze: PointMazeant_maze: AntMazewalker: Walkerfetch_push: FetchPushdoor: AdroitDoorkitchen: OpenMicrowavecar_racing: CarRacing (Image-based)
and 11 algorithms:
difo: DIFOdifo-na: DIFO-NAdifo-uncond: DIFO-Uncondbc: BCbco: BCOgaifo: GAIfOAIRLfO: AIRLfOwaifo: WAILfOot-lfo: OT (LfO)iq-lfo: IQ-Learn (LfO)depo: DePO
You can run the training scripts with Wandb sweep with the following commands:
./scripts/sweep <config_path>
# Example
./scripts/sweep exp_configs/point_maze/difo.yamlIf you prefer to run a single experiment in terminal, you can refer the commands and the parameters in the YAML files. For example, to train DIFO on PointMaze, you can run the following command:
python -m scripts.train_adversarial difo with difo sac_il 1d_condition_diffusion_reward point_maze algorithm_kwargs.bce_weight=0.1 reward.net_kwargs.emb_dim=128This project builds heavily upon the imitation library. All code under the imitation/ directory is sourced from their project. We deeply appreciate their contributions to the field of imitation learning.
This work builds upon several excellent open-source projects:
- imitation for core imitation learning algorithms and infrastructure
- Gymnasium for environment interface
- Stable-Baselines3 for RL algorithms
- D4RL for environments and demonstrations
- MuJoCo for physics simulation
This project is licensed under the MIT License. Key components have the following licenses:
- Code in
imitation/directory follows the MIT License from imitation
If you use this code in your research, please cite:
@inproceeding{huang2024DIFO,
author = {Huang, Bo-Ruei and Yang, Chun-Kai and Lai, Chun-Mao and Wu, Dai-Jie and Sun, Shao-Hua},
title = {Diffusion Imitation from Observation},
booktitle = {38th Conference on Neural Information Processing Systems (NeurIPS 2024)},
year = {2024},
}