![]()










An auto coding tool for python,off-brand github-copliot,trained by GPT2 transformer,fed with github public repos codes
It contains a GPT2 model trained from scratch (not fine tuned) on Python code from Github. Overall, it was ~80GB of pure Python code, the current model is a mere 2 epochs through this data, so it may benefit greatly from continued training and/or fine-tuning.
Input to the model is code, up to the context length of 1024.
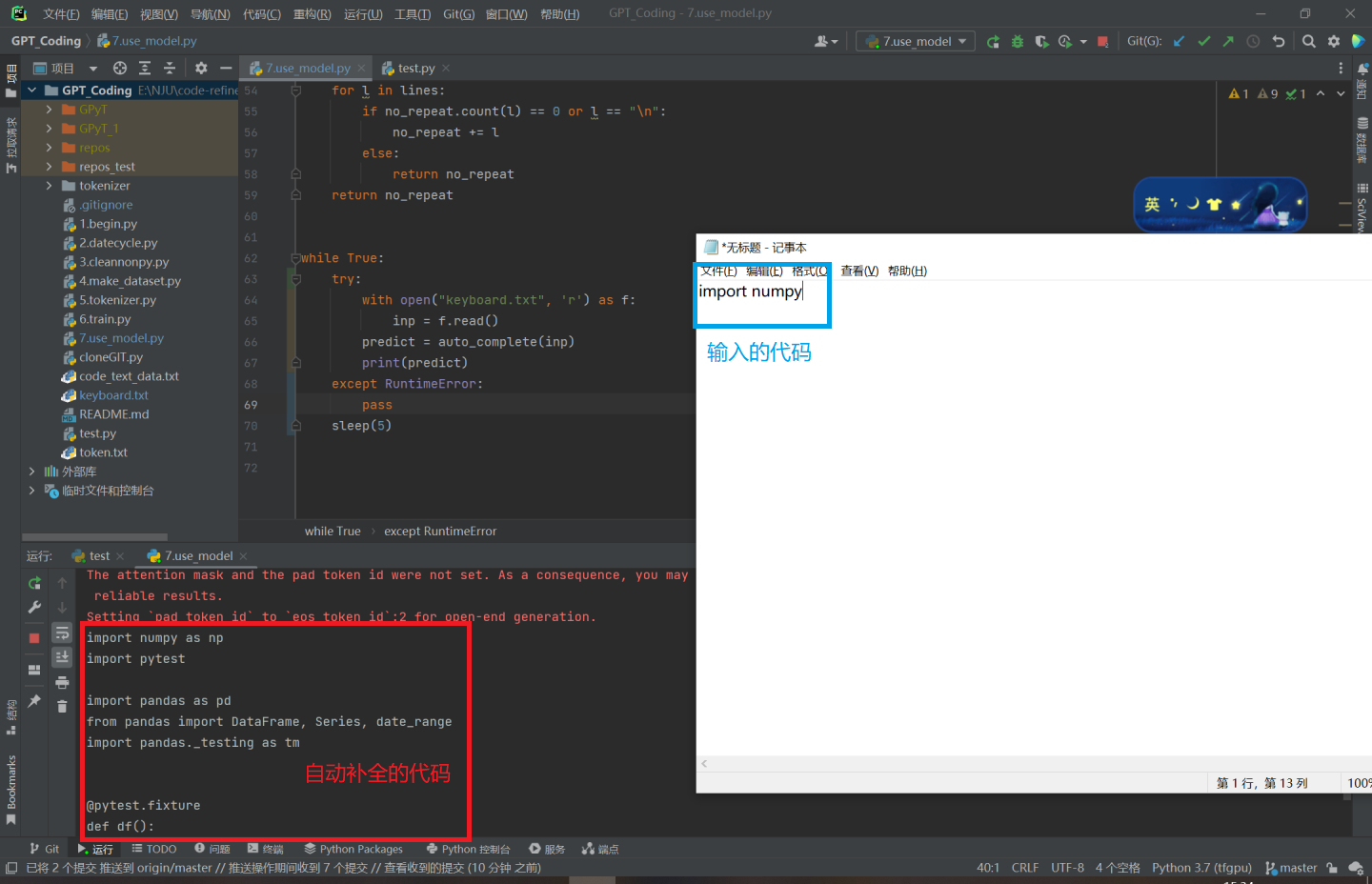
按照代码文件名中的数字顺序依次运行即可,不要忘记先运行test.py(开始敲代码前)!
注意把数据文件和模型放到指定位置,路径不要有中文。
也可以下载现成的模型直接运行7.use_model.py和test.py,享受低代码coding的乐趣!
下载地址:https://huggingface.co/Sentdex/GPyT/blob/main/pytorch_model.bin
test.py记录用户的键盘输入,并实时存入keyboard.txt,use_model.py异步读取txt中的内容,并通过训练好的模型进行预测。
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("Sentdex/GPyT")
model = AutoModelWithLMHead.from_pretrained("Sentdex/GPyT")
'''copy and paste some code in here'''
inp = """import"""
newlinechar = "<N>"
converted = inp.replace("\n", newlinechar)
tokenized = tokenizer.encode(converted, return_tensors='pt')
resp = model.generate(tokenized)
decoded = tokenizer.decode(resp[0])
reformatted = decoded.replace("<N>","\n")
print(reformatted)import numpy as np
import pytest
import pandas as pd